RFR: Active Vision
Proposed by Cerenaut and the Whole Brain Architecture Initiative
(What is a Request for Research/RFR?)
Summary
Background and Motivation
In the following, active vision means vision with eye movement.
The human eye has higher resolution in the fovea and lower toward the periphery. So, to gather detailed information from the entire visual field, the gaze must move around.
Since human vision requires active vision, AI that mimics humans also would require it. Thus, implementing active vision can be the first step for human-brain-inspired AI.
Active vision involves information processing that combines data collected from more than one time point (data binding), which requires short-term memory and a representation of “scenes” (situations). Eye movement is also apparently related to the mechanism of ‘attention.’ Information processing using short-term memory (working memory), handling of representations of situations, and the mechanism of attention can be regarded as basic functions for general intelligence and important for the realization of AGI (artificial general intelligence).
Objective
The task here is to implement biologically plausible active vision that can perform tasks requiring gaze motion.
For an overview of the system design, see Detailed Project Description below.
Success Criteria
The implementation will be judged with the following criteria:
- Biological plausibility
The implementation should be ‘compatible’ with the structure and function of the mammalian brain. - Usability
The implementation should be easily used and maintained together with documentation. - Specifications
See the Detailed Project Description section below. - Performance
Use one or more tasks from the Dataset and Test section below.
Detailed Project Description
Tasks that require Active Vision
Point to Target Task
The agent has to move the gaze to the position where a cue appears.
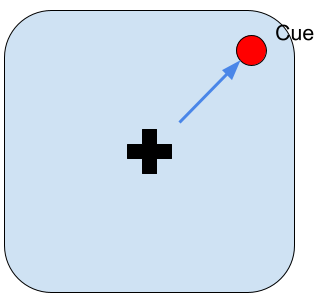
Fig.1
Image Recognition by Gaze Movement
The agent has to identify “scenes” that extend over the entire field of vision so that they can only be identified by moving the gaze. 
Scene 1: The cat is to the left of the door. Scene 2: The cat is to the right of the door.
Fig.2
Oculomotor Delayed Response Task
The agent has to move the gaze to the position where the cue was a few seconds after it disappeared. This simple task requires working memory.
 Fig.3
Fig.3
Other tasks
2018 WBA hackathon tasks: 7 tasks were used: i.e., Point To Target, Random Dot, Odd One Out, Visual Search, Change Detection, Multiple Object Tracking tasks. You need to analyze what kinds of abilities are required for the tasks before working on them.
In tasks known as Object Centric Learning, it is required to visually recognize where and what kind of objects are. More broadly, papers with code for visual reasoning can be found here.
Mechanisms to be Prepared
Peripheral and Central Visions
The agent processes the high-resolution image centered on the gaze position from the environment to produce peripheral and central image data.
The peripheral and central image data can be a single set of data, such as an image based on log-polar coordinates, or two sets of data corresponding to each.
The peripheral image could be in monochrome or polychrome.
Saccade and Saliency Map
The rapid eye movements to capture visual objects in the fovea are called saccades. The eye does not move randomly, but rather moves toward the most salient or “interesting” object. The saliency factors include differences in color, brightness, and movement from the surroundings. It has been hypothesized that there is a “saliency map” for the visual field.
Given a saliency map, it is necessary to design:
- the conditions (threshold, etc.) and timing of saccade
- how physically “realistic” to reproduce the motion (e.g., the eyeball is a sphere with mass and is driven by muscles)
- whether the relationship between the saliency map and eye movements should be determined by design or learned
Image Processing
You need to decide how to process the images (bitmaps) from the environment. First, design a method to create image data corresponding to peripheral and central vision; here an image processing library such as OpenCV can be used.
If image recognition is to be performed, the method should be chosen. If you use an artificial neural network (deep learning), you should also decide whether some pre-processing will be performed with image processing libraries. For an artificial neural network, the algorithm to be used should be determined. Since the brain does not use back-propagation in an end-to-end fashion, it would be necessary to incorporate an unsupervised learner such as an autoencoder to make it a brain-inspired AI.
Representing Scenes
Active vision combines data collected from points in time to create representations of ‘scenes.’ You have to design how you will combine the data. If you use an artificial neural network, one idea is to keep data from time points as the internal state of a recurrent neural network (RNN). Also, the representation of the scene must express ‘what and where.’ For this, you can design a certain coordinate system and a mechanism that associates the representation of the place (where) and the representation of the object (what).
Mechanisms for the tasks
Point to Target Task
The task is to move the gaze to the position where the cue appears. The “Saccade and Saliency Map” mechanism described above would be important for this task.
Image Recognition by Gaze Movement
Since the task is to identify “scenes,” it is necessary to implement the “scene representation” mechanism described above.
Oculomotor Delayed Response Task
While this task does not require advanced image processing, it does require remembering the location of the cue (working memory). A saliency map may be appropriated as the coordinate system.
Biological Plausibility
Our objective here is to implement an active vision imitating the human brain. While some neuroscientific literature will be presented below, the goal here is not to build a brain model, but to implement a “brain-inspired” artificial intelligence, so please refer to it insofar as you are interested.
Peripheral and Central Vision
The peripheral vision and central vision (fovea) are not clearly separated in the human vision, and the resolution decreases roughly “logarithmically” to the periphery. Though peripheral photoreceptor cells (rod cells) cannot distinguish colors, they are highly sensitive to light.
Saccade and Saliency Map
The saccade is driven by a part of the brain called the superior colliculus (SC) [Sparks 2000].
The saliency map is represented by more than one region of the brain including SC [Veale 2017].
Image Processing
Basic image processing performed in the visual system is known to include line segment detection, motion detection, and object/background discrimination. If you are interested in the human visual system, see Wikipedia on the visual cortex.
Representation of Scenes
An important mechanism in the visual system of mammals, including humans, is that there are two separate pathways , i.e., the what-path, which expresses what objects are, and the where-path which expresses the position and movement of objects (the two-streams hypothesis). Information from these two pathways is integrated in the entorhinal cortex, which is located near the hippocampus, to represent scenes. While information on gaze (eye) position would be necessary to describe a scene, it is not well understood where the brain obtains the information.
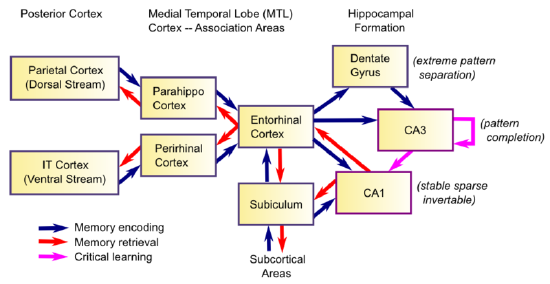
Fig.4 Hippocampal Anatomy
8: Learning and Memory is shared under a CC BY-SA license and was authored, remixed, and/or curated by O’Reilly, Munakata, Hazy & Frank.
Working Memory
While it is known that the prefrontal cortex is involved in working memory, the details of how it works are not fully understood.
Sample Architecture
A brain reference architecture to cover the mechanisms above is presented below based on the sample architectures used in the 4th WBA “Gaze Task” Hackathon and the 5th WBA “Working Memory” Hackathon (with a sample implementation).
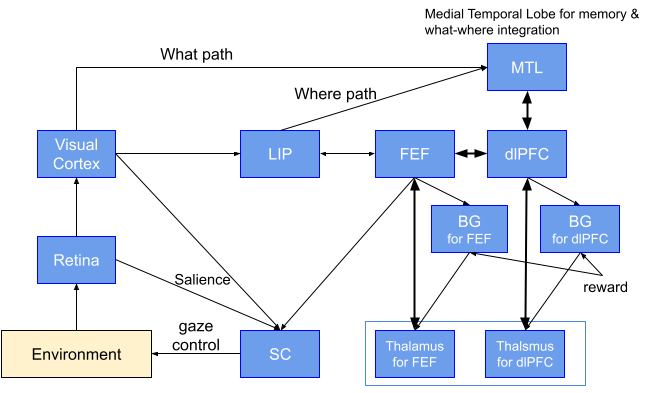
Fig. 5 Explanation: Information from the Retina enters the visual cortex, SC (the superior colliculus), LIP (the Lateral IntraParietal cortex), MTL (the medial temporal lobe), and dlPFC (the dorsal prefrontal cortex) successively. DlPFC controls execution such as working memory. FEF (the frontal eye field) provides gaze control. SC largely represents the saliency map and drives eye movements. In BG (the basal ganglia), which is attached to FEF and dlPFC, reinforcement learning takes place based on rewards from task-dependent environments.
Using BriCA
WBAI recommends using an architecture description framework for brain-inspired AI implementation called BriCA.
If the mechanism described above can be successfully incorporated into the sample architecture using BriCA, it could be reused in subsequent development. A BriCA implementation of the saliency map and gaze control can be found here.
Dataset and Tests
Task Environment
You have to prepare tasks you want the agent to solve. We recommend OpenAI Gym as the task environment framework and graphic environments such as PyGame (2D) and PyBullet (3D) can be used.
The task environment for the 4th WBA “Gaze Task” Hackathon is available (it is a re-implementation of DeepMinds’ PsychLab).
In the tasks mentioned above, actions are all gaze motions. The environment returns images to the agent as input according to the gaze position as well as rewards according to task status.
Background Information
Neuroscientific background information is referenced in the text.
Engineering background requires basic programming skills (especially Python). Basic knowledge of image processing libraries such as OpenCV would be a plus. For parts that require machine learning, basic knowledge of machine learning frameworks is required.
[Sparks 2000] David Sparks, W.H. Rohrer, Yihong Zhang: The role of the superior colliculus in saccade initiation: a study of express saccades and the gap effect, Vision Research, Vol. 40, Issue 20, (2000)
https://doi.org/10.1016/S0042-6989(00)00133-4.
[Veale 2017] Veale Richard, Hafed Ziad M. and Yoshida Masatoshi: How is visual salience computed in the brain? Insights from behaviour, neurobiology and modelling, Phil. Trans. R. Soc. (2017)
http://doi.org/10.1098/rstb.2016.0113

 Japanese
Japanese