Proposed by Project AGI (current Cerenaut) and the Whole Brain Architecture Initiative
(What is a Request for Research/RFR?)
Summary
Background and motivation
AI/ML has achieved revolutionary results in recent years, but the best techniques remain extremely simple in comparison to animal memory and learning. Additional capabilities include the ability to learn unique examples and unique sequences of events (episodes), the ability to prioritise learning by salience and to learn categories rapidly – often grouped together as ‘Episodic Memory’. An area of the brain called the Hippocampal system is known to be vital for declarative memory (both semantic and episodic) in the mammalian brain. This RFR is concerned with improving our understanding of that system to model the whole brain and improve current AI algorithms.
One of the most prominent computational models of the Hippocampus is the Complementary Learning System (CLS). CLS is well founded with neuroscientific evidence and accounts for many empirical findings. The model has been implemented and extended by several groups. CLS therefore is a good starting point for building an artificial hippocampus to improve memory and learning.
Objective
To implement CLS in a modern framework with widespread use in the ML community, so that others may play with and extend it.
This forms the first phase of an artificial hippocampus. The next steps (not in scope) will be to:
- Create a Hippocampal / Neocortical system by connecting it with a conventional pattern recogniser (as the neocortex)
- Extend the tests to include high dimensional datasets, and to tasks that cover the features of memory/learning described above (beyond variations of pattern completion)
Success Criteria
- A code base that can be installed and run with simple instructions, implemented with a popular framework such as Tensorflow
- The implementation follows the description of CLS (or close variation)
- Replication of results in latest CLS paper (Schapiro 2017)
Status
Semi-Closed. See the bottom of the page.
Detailed Project Description
The request is to implement the CLS Hippocampal model in a modern ML programming framework as a version 1 of an artificial Hippocampus.
Motivation
For the main part, state of the art AI algorithms such as deep learning consist of a module that learns categories or sequences based on statistical generalities. This is analogous to semantic memory, or memory for facts. Semantic memory is one aspect of declarative memory, the part that we are conscious of, the other being episodic memory. Episodic memory is often described as autobiographical, it is the memory of unique things and sequences of events. These features are likely to flow on to the ability to prioritise learning by salience and to learn semantic information rapidly.
It is recognised that the interplay between the Hippocampal system and the Cortex gives rise to these more advanced features of memory. Simplistically, machine learning models are analogous to the cortex, where long term semantic memory is stored. A better understanding and implementation of a Hippocampal/Cortical system is an opportunity for major improvements to AI systems through cognitive architectures and insights.
Complementary Learning System (CLS)
The central idea of CLS is that neocortex and the hippocampus comprise two complementary memory systems. The neocortex forms highly distributed and overlapping representations, excellent for inference and reasoning. The hippocampus forms much sparser and non-overlapping representations, specialised for fast learning of distinct instances and for facilitating interleaved replay which avoids the issue of catastrophic forgetting observed in neural network models.
The hippocampal system is depicted schematically below. The scope of this project is to model the Entorhinal Cortex (EC) and parts of the Hippocampal Formation: Dentate Gyrus (DG), CA3 and CA1. Don’t worry if this seems daunting! You don’t need to understand all these features to attempt this project.
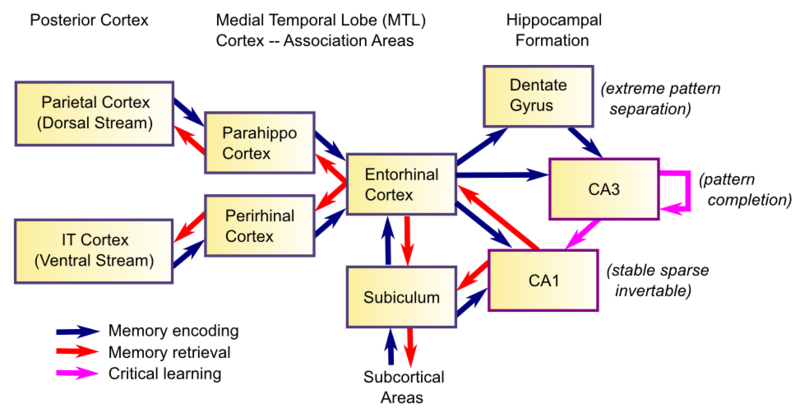
Figure 1: Hippocampal Memory Formation (from O’Reilly 2014)
We give a brief explanation here and provide resources for a more thorough treatment. The EC displays a sparse and distributed overlapping pattern that combines input from all over the neocortex. This pattern becomes sparser and less overlapping through DG to CA3 with increasing inhibition and compression. That provides independent representations for similar inputs and therefore an ability to separate patterns, important for learning about specific instances as opposed to generalities. Recurrent connections in CA3 allow partial cues to be expanded out into the original full pattern providing for pattern completion, which allows for learning about an association or conjunction of states (an event of episode). CA1 then provides a mapping back to the EC to present the original pattern for replay to the cortex, for recall and/or consolidation.
The CNNBook has an excellent chapter on CLS. It is well explained in the review (O’Reilly 2014). The original papers are also valuable for more thorough exploration of the biology and background (McLelland 1995, Norman 2003).
This RFR refers to Schapiro 2017 as the baseline implementation. It is recommended to read the paper. They provided working code here written with the neural simulation software Emergent. It will be useful to have a look at the code as a starting point.
The features of this implementation of CLS can be simplified as:
- Learn distinct events quickly, a form of ‘Episodic’ memory. This is few-shot learning of specific instances of conjunctions of inputs.
- Learn regularities within the statistics quickly, a form of fast ‘Semantic’ memory. This is fast learning of classes.
Dataset and Tests
There are 3 experiments to test learning regularities from statistics while being able to memorise distinct events. See (Schapiro 2017) for a detailed description of these tests. They are summarised here:
The EC is divided into ECin and ECout (with a connection from ECout to ECin). For each of the three tests, a sequence of characters are presented to ECin in a training phase. Then in a test phase, parts of the pattern are presented to ECin, and the associated complete pattern should be observed on ECout. The contents of the ‘complete’ pattern reflect structure in the input data.
- Episodes vs Regularities: The sequence of characters is organised into pairs. Each pair is consistently together and in the same order. This grouping is a distinct ‘event’ or Episode. Two characters are shown to the network at a time, so there is a window size of two. In one case, the window is incremented by two characters at a time, the Episodes are shown individually in sequence. In other words, the network must learn distinct events. In the other case, the window is incremented by one character at a time. The network sees the Episodes as well as boundaries between episodes, but the Episode pairs are observed more often. This requires learning statistics or learning regularities.
- Community Structure: The sequence of characters is generated by randomly walking a graph that has areas of dense connectivity (communities) sparsely connected to each other (see image below). There are boundary nodes that are directly connected to another community, and only indirectly connected to their own, however, they should be more strongly associated with their own community. The network must learn regularities from the statistics, beyond first order transitions.
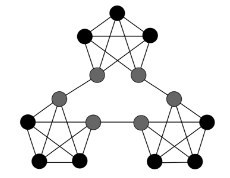
Figure 2: Graph with community structure (courtesy of Anna Schapiro) - Associative Inference: Sequential pairs of characters are shown frequently, and the association of these patterns should be learnt. For example, shown AB and BC, and learn the association of A and C. If A is presented to the network in the test phase, then C should be in the pattern completed.
Background Information
A Brief History of CLS
CLS was first introduced in (McClelland 1995) and implementations explored in (O’Reilly 2000, O’Reilly 2001). (Norman 2003) went further with more extensive testing including recall of vectors, pattern completion and distinguishing learnt inputs from distractors.
(Greene 2013) extended CLS with the goal of investigating the mechanisms by which the Hippocampus’ can learn within a context. The Lateral and Medial EC are known to receive distinct information, relating to context or object. They modelled these as separate structures, as well modelling differentiated structures within DG, CA3 and CA1. They also adopted the LEABRA framework which aims to be a more accurate model for synaptic consolidation than simple Hebbian learning. LEABRA is driven by local error gradients. It was trained online, preventing the need for pre-training some parts of the model. They studied the ability to recall visual objects given a context signal and vice versa, for different network configurations.
(Ketz 2013) also extended CLS with LEABRA, improving training speed and performance and avoiding pre-training as in (Greene 2013). Their model learnt a vocabulary of patterns, and was tested on retrieval under variations of network size and training style (Hebbian vs Leabra).
(Schapiro 2017) combined principles from Ketz’s model and ‘big loop’ recurrence from the REMERGE model (Kumaran 2012). They extended Ketz’s work by expanding the experiments to test and demonstrate the ability to learn distinct events quickly, as in previous studies, as well as learning regularities quickly. The former is often described as ‘episodic’ and the latter as ‘semantic’.
Related Work
As well as CLS, there are a number of other notable Hippocampal models. Gluck and Myers, described most recently in (Moustafa 2013), models the behaviour of the hippocampus more holistically, without attention to the biological subfields. Their model is based on the principle that the Hippocampus compresses similar patterns and makes the rarer patterns even more distinct. The Gluck and Myers model was used recently to build a simulated agent that in a 3d world (Wayne 2018). A detailed computational model similar to CLS is described by (Rolls 2017). It goes into more quantitative details that may be helpful.
References
- C. Schapiro, N. B. Turk-Browne, M. M. Botvinick, and K. A. Norman, “Complementary learning systems within the hippocampus: a neural network modelling approach to reconciling episodic memory with statistical learning,” Philos. Trans. R. Soc. B Biol. Sci., vol. 372, no. 1711, 2017.
- C. O’Reilly, R. Bhattacharyya, M. D. Howard, and N. Ketz, “Complementary learning systems,” Cogn. Sci., vol. 38, no. 6, pp. 1229–1248, 2014.
- L. McClelland, B. L. McNaughton, and R. C. O’Reilly, “Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory,” Psychol. Rev., vol. 102, no. 3, pp. 419–457, 1995.
- A. Norman and R. C. O’Reilly, “Modeling Hippocampal and Neocortical Contributions to Recognition Memory: A Complementary-Learning-Systems Approach,” Psychol. Rev., vol. 110, no. 4, pp. 611–646, 2003.
- Greene, M. Howard, R. Bhattacharyya, and J. M. Fellous, “Hippocampal anatomy supports the use of context in object recognition: A computational model,” Comput. Intell. Neurosci., vol. 2013, no. May, 2013.
- Kumaran and J. L. McClelland, “Generalization through the recurrent interaction of episodic memories: A model of the hippocampal system,” Psychol. Rev., vol. 119, no. 3, pp. 573–616, 2012.
- Ketz, S. G. Morkonda, and R. C. O’Reilly, “Theta Coordinated Error-Driven Learning in the Hippocampus,” PLoS Comput. Biol., vol. 9, no. 6, 2013.
- A. Moustafa, E. Wufong, R. J. Servatius, K. C. H. Pang, M. A. Gluck, and C. E. Myers, “Why trace and delay conditioning are sometimes (but not always) hippocampal dependent: A computational model,” Brain Res., vol. 1493, pp. 48–67, 2013.
For discussion, please join us in our reddit thread on Learning and Memory.
Status
This RfR is Semi-closed.
Cerenaut did a project themselves over the period of 2 years and the result is to be published.

 Japanese
Japanese{kind=link}