RFR:アクティブビジョン
Cerenaut および全脳アーキテクチャ・イニシアティブによる提案
Request for Research(RFR・研究依頼 )とは?
要約
背景と動機
以下ではアクティブビジョンを「視線移動を伴う視覚」と捉えます。
ヒトの目は中心窩部分で解像度が高く、周辺部に行くにつれて解像度が低下します。したがって、視野全体から詳細な情報を収集するには、視線をあちこちに移動させる必要があります。
ヒトの視覚がアクティブビジョンを必要としていることから、ヒトを真似た人工知能を作るにはアクティブビジョンを検討する必要があります。以下では、ヒトの脳を真似た人工知能実装の最初のステップとしてのアクティブビジョン実装について考えます。
アクティブビジョンでは、複数の時点から収集したデータを組み合わせた情報処理(バインディング処理)を行いますが、このためには短期記憶や「シーン」(状況)の表現を持っている必要があります。また、視線移動は一見して「注意」の仕組みとも関係していそうです。短期記憶を用いた情報処理(作業記憶)や状況の表現の扱い、注意の仕組みは一般知能(general intelligence)にとって基本的な機能であり、AGI (artificial general intelligence) の実現にとっても重要なものだと考えられます。
目標
視線移動を必要とする課題を実行でき、かつ生物学的な妥当性があるアクティブビジョンシステムを実装することが、ここでの依頼です。
システム設計の概要については下記「プロジェクト内容の詳細」の節を参照ください。
成功基準
実装は以下の基準によって評価されます。
- 生物学的な妥当性 (biological plausibility)
哺乳類の脳の構造や機能についての知見と齟齬がないこと - 使いやすさ(usability)
文書化されていて、使用と維持が容易なように実装されていること - 仕様
下記「プロジェクト内容の詳細」の節を参照ください - 性能
下記「データセットとテスト」の節にある課題を一つ以上お使いください。
プロジェクト内容の詳細
アクティビジョンを必要とするいくつかのタスク
視線移動タスク(Point to Target Task)
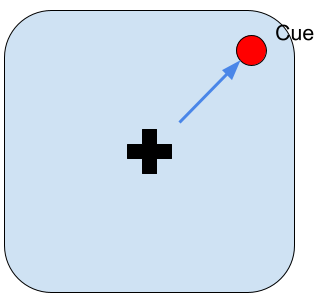
図1:キューが現れた位置に視線を動かします。
視線移動による画像認識タスク
視線を動かすことではじめて識別できるような視野全体に広がる「シーン」を識別します。

シーン1:猫がドアの左にいる。 シーン2:猫がドアの右にいる。
図2
作業記憶タスク(Oculomotor Delayed Response Task)
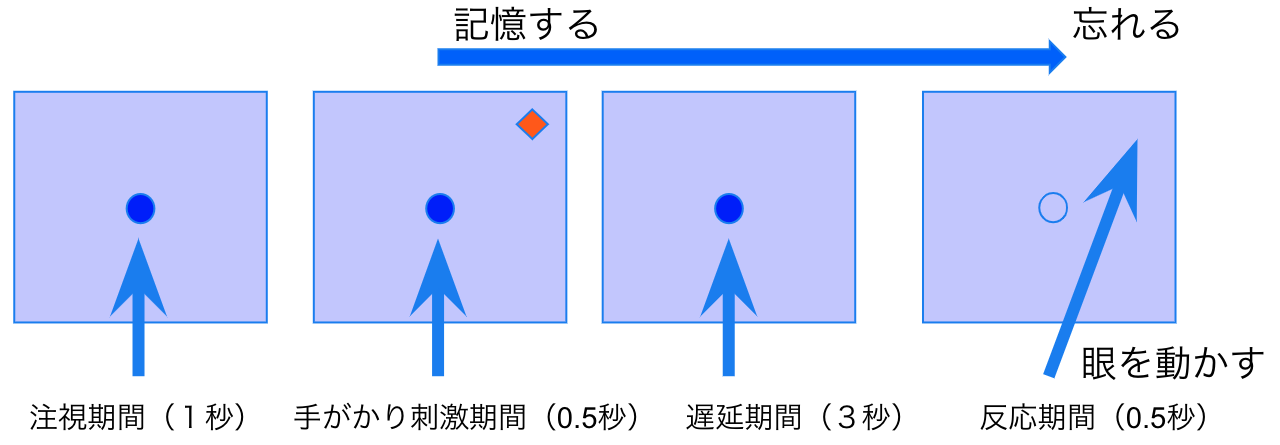
キューが消えてから数秒後にキューがあった位置に視線を動かします。
図3
その他のタスク
2018年の WBAI ハッカソンのタスク:Point To Target、Random Dot、Odd One Out、Visual Search、Change Detection、Multiple Object Tracking という7つのタスクが用いられました。それぞれが視線移動以外にどのような能力を必要とするか分析する必要があります。
機械学習分野では、視野内にどこにどのような対象があるかを認識する Object Centric Learning というタスクが知られています(英文記事)。より一般的に visual reasoningと呼ばれる分野の紹介記事と論文リストがこちらにあります。
用意すべき仕組み
周辺視と中心視の仕様
エージェントは環境側から入力される視線位置を中心とする高解像度画像を加工して周辺視と中心視に対応する画像データを作り出します。
周辺視と中心視に対応する画像データとしては、例えば対数極座標のような単一のデータを用いることもできますし、それぞれに対応する2種類のデータを生成して用いることもできます。
周辺視をモノクロにするかどうかも決めておく必要があります。
Saccade とサリエンシーマップ
周辺視野に見える対象を中心視野にとらえる際におきる素早い眼球運動を saccade と呼びます。視線はランダムに移動するわけではなく、最も目立つ(salient な)あるいは「気になる」対象に向けて視線が動きます 。「目立つ」要因としては周囲との色や明度の違いや、動きなどを挙げることができます。視野内の位置の「目立ち度(saliency)」のマップがあるという仮説が提唱されています。
サリエンシーマップが与えられたとして、saccade をどのような条件(閾値など)やタイミングで起こすかを設計しておく必要があります。実際の眼球は質量を持った球体で筋肉によって駆動されますが、どこまで物理的に「リアルな」動きを再現するのかも決める必要があります。また、サリエンシーマップと眼球運動の関係を設計で決め打ちするのか、学習させるのかも決めておく必要があります。
※少し別の考え方として、知覚から得られる仮説を検証するのに最も適しているであろう対象に向けて視線を動かすという考え方もあります(参考:「アクティブビジョンと フリストン自由エネルギー原理」)。
画像処理
環境から入力される画像(ビットマップ)の処理方法を決める必要があります。まず、周辺視と中心視に対応する画像データを作る方法を設計します。OpenCV などの画像処理ライブラリを利用できないか検討します。
画像認識を行う場合、その仕組みを検討します。人工ニューラルネット(深層学習)を用いる場合も、画像処理ライブラリで何らかの前処理をするかどうかを決めておきます。人工ニューラルネットについてはどのようなアルゴリズムを使うかを検討します。脳型AIでは end-to-end の形で逆誤差伝搬手法を用いることはできないので(脳には全体的に誤差を逆伝搬する仕組みがないため) 、オートエンコーダのような教師なし学習器を組み込む必要があります。
シーンの表現
アクティブビジョンでは、複数の時点から収集したデータを組み合わせて「シーン」の表現を作ります。データをどうやって組み合わせるかを設計しておく必要があります。人工ニューラルネットを用いる場合、RNN (recurrent neural network) の内部状態として複数時点のデータを保持するということが考えられます。また、シーンの表現では、どこに何があるかということを表現しなければなりません。このためには、なんらかの座標系表現を用い、場所(どこ)の表現とオブジェクト(何)の表現を相互に連想するような仕組みを考えることができます。
タスクごとの仕組み
視線移動タスク
キューが現れた位置に視線を動かすタスクです。上記「Saccade とサリエンシーマップ」の仕組みが重要な部分となります。
視線移動による画像認識タスク
「シーン」を識別するタスクなので、上記「シーンの表現」の仕組みまでを実装する必要があります。
作業記憶タスク
上記作業記憶タスクでは高度な画像処理は必要ありませんが、キューの場所を覚えておく必要があります。座標系としてはサリエンシーマップを流用することができるでしょう。
脳との関連付け
ここでは、ヒトの脳を真似たアクティブビジョン実装を考え、上で書いたエージェントの仕組みがヒトの脳でどのように実装されているかの概略を説明します。神経科学的な文献も紹介しますが、ここでの目的は脳のモデルを作ることではなく「脳にヒントを得た」人工知能を実装することなので、ご関心の範囲で参考にしてください。
周辺視と中心視
中心視と周辺視ははっきりわかれているわけではなく、周辺に行くにつれて概ね「対数」的に解像度が低下します(参考:小寺 宏曄: 簡便な中心窩イメージング法)。また、周辺部にある視細胞(桿体細胞)は色を識別することができませんが、光に対して高い感度を持ちます。
網膜から大脳視覚野にいたる情報処理については、こちらの(浅川先生の)ページを参照ください。
Saccade とサリエンシーマップ
サリエンシーについては、上でも紹介したように脳科学辞典に概説があります。
Saccade は脳内の上丘(superior colliculus SC)と呼ばれる部位により駆動されます。仕組みについては例えばこちらを参照ください。
画像処理
視覚系で行われる基本的な画像処理としては、線分検出や動きの検出、対象と背景の区別といったものがあることが知られています。ヒトの視覚系に興味のある方は、Wikipedia の視覚野の記事、中村晃貴氏(全脳アーキテクチャ若手の会)の解説スライド、浅川先生の解説、脳科学辞典の受容野の記事などを読んでみてください。
シーンの表現
ヒトを含む哺乳類の視覚系で重要な仕組みとして、対象が何かを表現する what-経路と対象の位置や動きを表現する where-経路が別れていることを挙げることができます(図4)。これら2つの系統の情報は嗅内野(entorhinal cortex)という海馬(hippocampus)の近くにある部位で統合され、シーンを表現することになります。シーンを表現するには視線(眼球)位置の情報が必要だと考えられますが、その情報を脳がどこから得ているかについてはよくわかっていないようです。
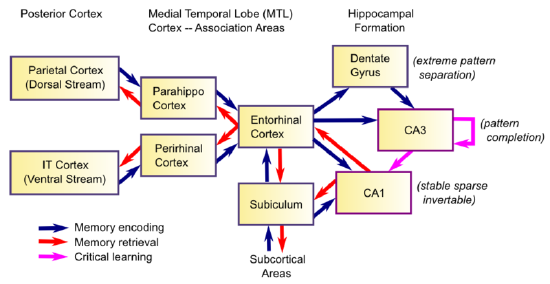
図4:Hippocampal Anatomy
8: Learning and Memory is shared under a CC BY-SA license and was authored, remixed, and/or curated by O’Reilly, Munakata, Hazy & Frank.
作業記憶
作業記憶については前頭前野が関係していることはわかっていますが、詳しい仕組みはわかっていません。
サンプルアーキテクチャ
第4回WBA「視線タスク」ハッカソン、第5回WBA「作業記憶」ハッカソンで用いられたサンプルアーキテクチャをベースに、上記の仕組みをカバーするような脳参照アーキテクチャを以下に示します。
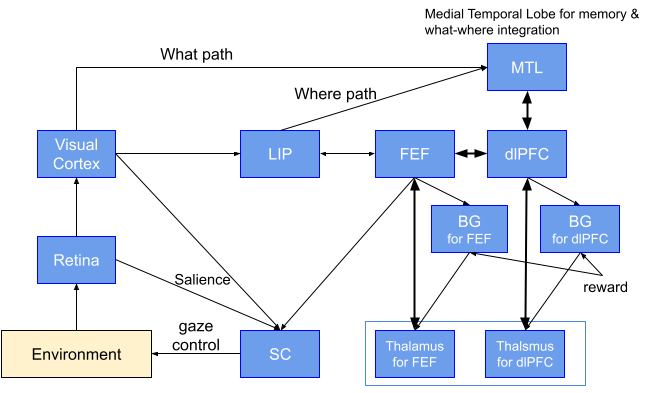
解説:眼球(Retina: 網膜)からの情報が視覚野(Visual Cortex)とSC(上丘)に入り、さらに LIP( 頭頂間溝外側領域)、内側側頭葉(MTL)、背側前頭前野(dlPFC)へと流れます。背側前頭前野(dlPFC)は作業記憶などの実行制御を行います。FEF(前頭眼野)は視線制御を行います。SC(上丘)は概ねサリエンシーマップを表現し、眼球運動を駆動します。FEFとdlPFCに対応する大脳基底核(BG)ではタスク依存の環境からの報酬に基づいて学習(強化学習)が行われます。
なお、第5回(作業記憶)ハッカソンではアクティブビジョンアーキテクチャのサンプル実装を提供しています。参考にしてみてください。
BriCAの利用
WBAIでは、BriCA と呼ばれる脳型AI実装のためのアーキテクチャ記述フレームワークの利用を推奨しています。サンプルを含めた詳しい記述についてはこちらを参照ください。
上で書いた仕組みをBriCA を使ってサンプルアーキテクチャにうまく組み込めれば、その後の開発での再利用の点でメリットがあります。なお、Saliency Map と視線制御についての BriCA による実装があります(記事)。
データセットとテスト
タスク環境
実装するエージェントに解かせてみたいタスクを用意します。PyGame(2次元)や PyBullet(3次元)などのグラフィック環境を OpenAI Gym から呼び出す形になります。
なお、第4回WBA「視線タスク」ハッカソンで用いられたタスク環境(DeepMind の PsychLab を再実装したもの)はこちらにあります。
環境へのアクションは、上に挙げたタスクに関してはすべて視線の位置ということになります。環境は視線の位置に応じた画像をエージェントに入力として返します。また、タスクの状況に応じて報酬をエージェントに与えます。
予備知識
神経科学的な予備知識については本文中に参考文献を挙げました。
工学的な予備知識としては、基本的なプログラミングスキル(特に Python)が必要です。OpenCV などの画像処理ライブラリの基本的な知識もあるとよいでしょう。機械学習を必要とする部分については、機械学習フレームワークの基本知識が必要になります。

 English
English