Proposed by Project AGI (current Cerenaut) and the Whole Brain Architecture Initiative
(What is a Request for Research/RFR?)
Summary
Overview
The brains of all bilaterally symmetric animals on Earth are Bicameral, that is, they are divided into left and right hemispheres. It is a remarkably conserved feature across species, indicating its importance for intelligence. The anatomy and functionality of the hemispheres have a large degree of overlap, but they specialise to possess different attributes. The most likely explanation for the emergent specialisation, is small differences in parameterisation of the substrate. For example, a higher rate of synaptic plasticity in one hemisphere, different relative layer sizes and different connectivity patterns within and across layers. The biological parameterisation could be equivalent to hyperparameters of an AI Machine Learning algorithm.
There could be great benefits to understanding and mimicking this pervasive design feature of biological intelligence by building bicameral ML algorithms – two parallel systems with different specialities. To our knowledge, this has never been explored. It has the potential to confer significant advantages and is an exciting prospect. The way to approach it is an open question, we can be inspired and guided by neuroscience models.
Objective
The objective is to build a bicameral Machine Learning model with hemispheres resembling the biological counterparts. This will form the basis for further explorations of bicameralism, including interplay with other brain and neurotransmitter systems.
Success Criteria
A successful project will include algorithm design, implementation, experimental setup and results including comparison to benchmarks on conventional algorithms.
Status
Open. See the bottom of the page.
Detailed Project Description
This project involves building a bicameral ML system that mimics the hemispheric differences in biological neocortex. The functional and structural differences are summarised in a table in the section Background Information below.
The working hypothesis is that narrow vs broad class definitions enable the hemispheres to specialise in familiar vs novel stimuli respectively. This concept forms the basis of this investigation. Can we emulate this in an ML algorithm and can specialised hemispheres be combined for superior performance?
In terms of the other items in the table, the learning rate is probably an important factor for the broad vs narrow specialisation to emerge, although unlikely to have the same effect in a conventional ML algorithm. Short vs long pathways are likely also an emergent consequence, or possibly an underlying learning rule; that is out of scope. Salience and involvement of neuromodulators are related to higher order decision making and are also out of scope.
The project can be approached in the following two stages, first with single layer networks, and then moving on to hierarchical networks.
Stage 1 – Broad vs Narrow Classes
The first part is having an algorithm that can learn narrow or broad classes by modifying the hyperparameters.
There are many ways this could be achieved and we leave this open, it is part of the scope of the project.
One suggestion is to use a k-sparse autoencoder. In a k-sparse autoencoder, each active neuron represents a range of variation. Increasing sparsity (i.e. less active bits) forces neurons to represent coarser features, as can be seen in the Figure below. Therefore, varying sparsity may be an effective way to vary the breadth of class definitions.
cf. see Figure 1 of Makhzani and Frey [5]
Prepare a dataset with two test subsets, one that is very similar to the training set, and one that is less similar to training set. The Omniglot dataset provides a huge range of alphabets, so this may be a good base dataset to use.
Use these two datasets to test the performance of your algorithm as you vary the hyperparameters, including number of neurons. In particular, is there a tradeoff between accuracy on the two datasets that you can tune? Establish a benchmark first and compare to this as you go.
The tests can be done supervised or unsupervised, it is up to you and dependent on the datasets you choose and how the training is performed. The concept of similarity between classes is perhaps more compatible with unsupervised learning, where you are essentially learning a lower dimensional representation without forcing strict distinctions between class types. In that case, it is common practice to use an additional simple discriminative algorithm (such as logistic regression) to test the unsupervised model’s output features. For supervised learning, it would be interesting to explore the idea of explicitly training on multiple class labels of varying breadth e.g. [Object=Ferrari, Label=’Car’], [Object=Ferrari, Label=Vehicle].
Stage 2 – Combining Output
Once a suitable base algorithm has been selected, you can create a single layer bipartite network, with two separate hemispheres, Left and Right. The Left will be set up to have narrower class representations, and the right broader.
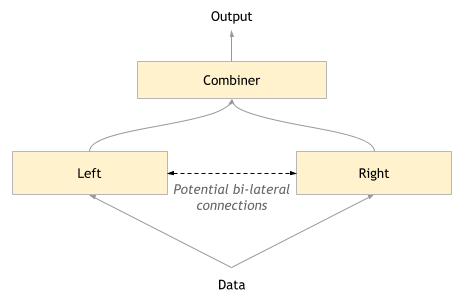
The next research question is how can the outputs be combined? Again, this is an open question, but we make 3 proposals which can be investigated.
- The Combiner selects a winner. This is akin to competitive inhibition. The way to select a winner will depend on the base algorithm used.
- The outputs are concatenated into one output.
- An additional algorithm/network learns to combine the two outputs appropriately.
In more advanced stages, we can look at lateral connections as well as feedforward and feedback via the Combiner.
The same tests can be repeated, but now we expect to be able to overcome the tradeoff, and be effective at both datasets. Not only that, but the system should be more effective than when using either Left or Right alone. For a fair comparison, increase the resources of either hemisphere, to that of both combined, when used in isolation.
Background Information
The table below summarises some of the major differences between the hemispheres. See [1,2,3,4] and other texts for detailed descriptions.
| LEFT HEMISPHERE | RIGHT HEMISPHERE |
| Functionality: Specialises in … | |
| Faster learning rate | Slower learning rate |
| Narrow class definitions | Broad class definitions |
| Familiarities/Routine
These trigger the specific class representations. |
Novelty
When an object is new and does not fit one of the narrow definitions, it can be handled by the more general, broad class representations of the right hemisphere. |
| Salience-driven cognition | |
| Structure: Overrepresentation of … | |
| Short local pathways, modular network organisation. Potentially deep network with long local connectivity. | Long inter-regional pathways, Small world network. I.e. Shallow network. |
| Modality-specific association cortices. | Heteromodal association cortices. |
| *More dopaminergic relative to norepinephrine projections (routine) | *More norepinephrine relative to dopaminergic projections (novelty) |
Significant communication between the hemispheres occurs via a bundle of fibres called the corpus callosum. The projections are both inhibitory and excitatory.
References
[1] E. Goldberg et al., “Hemispheric asymmetries of cortical volume in the human brain”, Cortex, 2013 [pdf]
[2] E. Goldberg, Creativity: “The Human Brain in the Age of Innovation”, Oxford University Press, 2018
[3] E. Goldberg, “The New Executive Brain”, Oxford University Press, 2009
[4] E. Goldberg and L. Costa. Hemisphere differences in the acquisition and use of descriptive systems, Brain and Language, 1981, 14, pp. 144-173
[5] A. Makhzani and B. Frey, “k-Sparse Autoencoders”, arXiv:1312.5663v2, 2013
[6] E. Goldberg et al., “Cognitive bias, functional cortical geometry, and the frontal lobes: laterality, sex, and handedness”, J Cogn Neurosci. 1994 Summer;6(3) pp. 276-96
doi: 10.1162/jocn.1994.6.3.276.
* Dopamine (DA) and norepinephrine (NE) are important neurotransmitters in the brain. Dopamine is used to signal salience and strengthens memory formation. It is important for more routine narrow tasks. NE is important for novel tasks. Interplay and balance between these systems are vital for effective cognition. Dopamine is released through dopaminergic projections from a region called the Ventral Tegmental Area (VTA). The VTA itself receives salience signals from the amygdala and prefrontal cortex, from an emotional and analytical standpoint respectively.
Status
This RfR is Open.
A project was conducted as a Monash Uni Masters project in 2021. It investigated unsupervised learning and parameter differences. The project continued with supervised learning in 2022 and will be published (preprint).
Currently there is a new Masters student extending it to explore specialization in more detail.

 Japanese
Japanese