Project AGI および全脳アーキテクチャ・イニシアティブによる提案
Request for Research(RFR・研究依頼 )とは?
要約
背景と動機
知的なエージェントは意思決定を行います。したがって、人間の知能のような「汎用人工知能 (AGI) 」の実現を目指すのであれば、それがどんなプロジェクトであったとしても意思決定をモデル化する必要があります。
汎用人工知能を創り出すために、私たちは、全脳アーキテクチャ・アプローチ、すなわち、脳全体の構造に学ぶという方法を追求してきました。ここでは、哺乳動物の脳が行っている意思決定をモデル化することを提案します。
これまでに多くのモデルが提唱されてきていますが、 オライリーの計算論的認知神経科学の教科書 (以下、CCNBook と呼びます)のモデルを標準的なものとして参照することにします。このオライリーのモデルでは、意思決定には、前頭皮質と大脳基底核 およびその周辺諸領域によって構成されているループ がもちいられていると想定されています。このループは、Actor-Critic法 によって意思決定を強化します。
目標
生物学的な妥当性がありつつ、しかも計算論的に効率的であるような意思決定のモデルを実装することが、ここでの依頼です。
作られるモデルは、脳にヒントを得ながら知能のモデルを作る際に、参照モデルとして用いうるものでなくてはなりません。したがって、あなたが実装するモデルは、コミュニティのなかで使われたり、維持されたりすることができるように、できるだけシンプルでなくてはなりません。
どのようなモデルとして実装されるべきなのか、以下のプロジェクト内容の詳細に概要を記します。
状況
Open
👉 ページ最下部
成功基準
実装されたモデルは以下の基準によって評価されます。
- 生物学的な妥当性 (biological plausibility)
哺乳類の脳の構造や機能についての知見と齟齬がないこと - 使いやすさ(usability)
文書化されていて、使用と維持が容易なように実装されていること - 仕様
以下のプロジェクト内容の詳細の節を参照ください - 性能
以下のデータセットとテストの節にある課題を一つ以上お使いください。
プロジェクト内容の詳細
ここで提案させていただくのは、以下のようなモジュールからなる意思決定モデルを実装することです。
※これらのモジュールは CCNBook のモデルをリファクタリングしたもの です。
- FCモジュール〔Frontal Cortex 前頭葉〕
- 外部からの入力に基づいて複数の選択肢を提供する
- ここで意思決定のための勝者総取り(winner-takes-all)ロジックを実装していてもよい
- ここで選択肢の得点を蓄積するためのaccumulatorロジックを実装していてもよい
- 再帰型ネットワーク reccurrent networks を用いてもよい
- Actorモジュール
- 大脳基底核 (BG) および視床の一部に対応する
- 選択肢それぞれの強さを調整する
- Criticから学習のための TD信号 を受け取る
- 外部からの状態入力を受け取る
- ここで意思決定のための勝者総取り(winner-takes-all)ロジックを実装していてもよい
- Criticモジュール
- 大脳基底核 (BG) および扁桃核の一部に対応する
- 外部からの報酬に基づいた TD信号 を創り出す
- 外部からの状態入力を受け取る
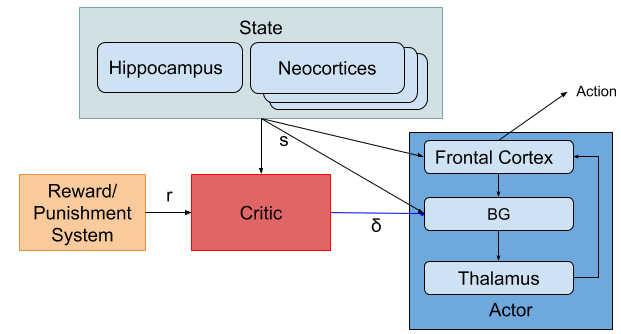 状態 state, 海馬 Hippocampus, 大脳新皮質 Neocortices, 報酬系 Reward/Punishment System, 前頭葉 Frontal Cortex, 大脳基底核 BG, 視床 Thalamus
状態 state, 海馬 Hippocampus, 大脳新皮質 Neocortices, 報酬系 Reward/Punishment System, 前頭葉 Frontal Cortex, 大脳基底核 BG, 視床 Thalamus
図1:システムの全体図
ActorとCriticは両者とも大脳基底核の一部を含みます。
モデルの特性:
実装していただくモデルには以下のような動作特性が備わっていなくてはなりません。(これらの制約条件についての議論としてはこちら を参照ください)
- ハイパーパラメータをほとんど持たないこと:ハイパーパラメータは自動的に順応するか、または、時間経過に対して不変でなくてはならない
- 必要であれば一つ以上の行動を同時に選択する可能性
- 葛藤の解消:両立不可能な複数の行動選択を排除するための、何らかの方法
- クリーン・スイッチング:逡巡している状態に陥ることなく、素早く明確に、僅かなりともよりよい行動が選択されること
- 完全選択:選ばれなかった選択肢は選ばれた選択肢に干渉してはならない
実装のための計算論的なツール:
十分な信頼性を備えたものであれば、どんな機械学習アルゴリズムやオープンソース・フレームワークを使って実装していただいても構いません。
例えば、オライリーのグループによって提供されている emergent が用いているような生物学的な妥当性のあるアルゴリズム(すなわち、ヘブ学習)を使うことも考えられます。
なお、新たな実装は、例えば emergent における実装より「使いやすく」なっていなくてはならないことにご注意ください。
プログラミング言語にかんしては、私たちはPython をおすすめします。
モジュールは十分に「カプセル化」していただくようお願いします。これは、いろいろな開発者チームのあいだでのより優れた相互運用性を得るために、各モジュールが何らかの混成的なフレームワーク環境(例えば、 TensorFlow と Caffe でもって実装を混合すること)においても大規模な修正なしに再使用できるようにするためです。
ちなみにWBAIは、脳の構造に着想を得た計算法自前のフレームワーク(BriCA)を開発しています。
ツールの問題につきましては、この依頼に基づいた研究を開始する前にぜひ私たちと話し合っていただきたいと思っています。
データセットとテスト
今のところ、私たちは自前のデータセットやテストバッテリーを提供してはいませんが、CCNBook の Executive Function の章や Psytoolkit.org の実験ライブラリには、意思決定モデルのためのテストへの言及があります。実装をテストするために、ここにある一つ以上の課題を選ぶとよいでしょう。
なお、これらのテストのほとんどは作業記憶のテストも行うので、作業記憶のテストにもなっています。
- 課題スイッチング課題 Task switching tasks (psytoolkit.org):
- ウィスコンシン・カード課題 Wisconsin card sorting task (WCST)
- 次元変更カード課題 Dimensional change card sorting task (DCCS)
- Nバック課題(N-Back task)(Wikipedia)
- ストループ課題 (CCNBook) / (Psytoolkit.org) (Wikipedia)
- ストア・イグノア想起課題 Store-Ignore-Recall (SIR) task (CCNBook)
- A-not-Bエラー (CCNBook) (Wikipedia)
予備知識
CCNBook の以下の章が、このRFRに関連しています。
オライリーのモデルは作業記憶のモデルでもあることにご注意ください(前頭前皮質大脳基底核作業記憶モデル:PBWM )。
また、ここに示されたモデルは、出発点として過度に単純化されたものであることにもご注意ください。例えば、意思決定のアキュミュレータ(ランピング) [Simen 2012]という側面についても考慮に入れたほうがよいかもしれません。
また、Scholarpediaの行動選択についての記事も参照ください。
さらなる議論については、意思決定についての私たちの reddit のスレッド Decision Making(英語)にご参加ください。
状況
Open
このRfR に関連する1つの実装 が行われました。

 English
English